AlphaPasso
Passo
Passo by the publisher Steffen Spiele and Helvetiq, is a two-player game with minimal components and ruleset. Despite the simplicity, Passo offers a really engaging gameplay where the game “board” slowly shrinks as the game progress. The game board consists of a 5x5 grid constructed with square tile pieces and each player controls 5 disk pieces located at top and bottom most rows as starting positions. On their turn, a player moves one of their disks one space in any orthogonal or diagonal direction. Tiles where the disk were moved from are taken out from the game if they no longer contain any pieces. Furthermore, isolated tiles (where all its 8 neighbors no longer exist) must be removed as well. Players can move their disk to another tile with existing disks as long as the stack height does not exceed 3. Trapped pieces in the stack cannot be moved (player can only move the top most piece of their own color).
The game ends when the current player can no longer make a valid move, in such case the other player wins the game. Alternatively, whichever player manages to move past the opponent’s disk closest to their opponent wins. For this case, a move off the board is considered valid. The game also offers an advanced variant which involves special power tokens, however for this project we will stick to the basic rule. More information about the game can be found in the BoardGameGeek(BGG) page or the publisher’s site.
Methodology
Passo falls under a category of combinatorial game with perfect information. This type of game is often where computer can surpass human. Probably the most famous example is the Google DeepMind AlphaGo, where the trained model was able to score 4-1 victories against the legendary Korean Go player - Lee Sedol. AlphaGo is the successor of the (simplified) AlphaZero model used in this project. In essence AlphaZero combines deep neural network and Monte Carlo Tree Search to predict the best move given a game state.
This project is similar in spirit with the AlphaMiniBoop project by Kiwimaru. In that project, Kiwimaru developed and trained the AlphaZero model to play another abstract combinatorial game called “Gekitai”. A BGG post about the project can be found here and the github repo can be found here. Note that the github repo also contains Gekitai’s successor game called “Boop”. If you are a fan of abstract games and cats, you should definitely check this game out. For my project, I am using the same AlphaZero framework that Kiwimaru used and I only need to implement the game/board logic. This mainly involves implementing Board and Game classes.
The Board class includes these important functions: get_valid_moves, move_piece, get_win_state. These functions are relatively easy to implement, the tricky thing is to make sure the behaviors are correct especially related to isolated tiles and trapped pieces. To help me verify the correct behaviors I did end up writing test cases for each functions. This verification step is important to prevent training the model with bad data. Additionaly the tests will help me make sure nothing breaks if in the future I plan to improve the code. I should probably profile the code as well to see where the bottlenecks are.
On the other hand, the Game class implement the GameState interface needed by the training process, specifically: valid_moves, play_action, win_state, and observation. valid_moves and win_state utilize some functions defined previously in the Board class and then format the results to be compatible with the interface. observation returns a 10-channel tensor for the neural network. The channels are broken down as follow: 3 channels each for the player piece on the stacks (2x3=6 in total), 1 channel for stack height normalized, 1 channel for top piece owner, 1 channel for player turn, and 1 channel for tile existence.
Once the Board and Game classes are ready, the training process is as simple as running the train.py script. In the train.py we need to import the game module and specify some training parameters. The training process then generates .pkl files that can later be loaded for best move prediction.
For the visualization and user interface of the game I am using PyGame. Specifically I am using Model-View-Controller pattern for the architecture. The Model component will handle the logic of the game, I will be using the same Game class previously used for the model training. The Controller module will handle the user interaction with the game, in this case it will handle the user click events for picking up and dropping the disk pieces. Lastly, the View module is responsible to render the state of the game. All these modules are integrated inside the Main module which also be responsible for constructing the AI agent (loading the model checkpoint).
Result
Below is the graph showing the progress of the Elo rating of the model, note that this rating is generated through self play of current iteration and randomly selected list of previous iterations. It is not a measure of absolute strength of the model but it is a relative measure of how much stronger the model becomes as the training progresses. After 40 training iterations, the Elo rating stabilized around 2000. 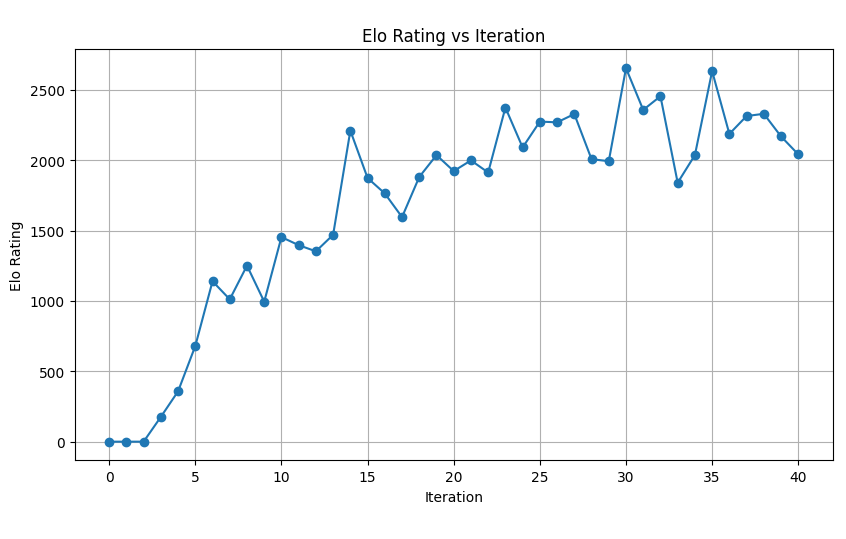 Below are the GIFs showing 2 game sessions between me and the AlphaPasso. The GIF on the left shows a game session at which I was able to win the game, while the one on the right shows a session where AlphaPasson won. Red and Black disks are controlled by me (Player 1) and AlphaPasso (Player -1) respectively.
Below are the GIFs showing 2 game sessions between me and the AlphaPasso. The GIF on the left shows a game session at which I was able to win the game, while the one on the right shows a session where AlphaPasson won. Red and Black disks are controlled by me (Player 1) and AlphaPasso (Player -1) respectively.


As a rough measure I played 10 games back to back and managed to only win once. See the GIF below for the captured game sessions where AlphaPasso is the winner. I am by no means an expert Passo player but I think the AlphaPasso model came out to be a strong one. In fact, I am quite happy with the result. You might ask, will playing board games against AI replace playing them in real life? Absolutely not, at that point I would rather play video games but then I am trying to spend less time staring at computer screen. Some of the most enjoyable aspects of playing board games in my opinion come from the tactile sensation of handling the game pieces and also the live interaction between human players.

Future work
I think incorporating the special powers (as included in the advanced rules) would be a fun addition, but for the next iteration of the project I plan to focus on bringing the physical aspect of playing board games into realization instead. This will entail using actual game pieces and a robot arm to execute the AI moves.
Before going directly to hardware I think the next iteration of the project will still benefit from simulation environment. Here are the pieces I need to figure out:
Robot motion
- Simulation using NVIDIA Isaac Sim or Gazebo
- MoveIt for motion planning
- BehaviorTree for high level plan execution
- ROS2 control for low level control
Game state evaluation/detection
- OpenCV to detect grid/tile pieces
- Camera placement - end effector vs fixed
- Camera calibration
Deployment
- Robot platform: SO‑101 arm or Robotis OMX arm